


L’intelligence artificielle peut donner l’impression qu’elle est immatérielle. Son fonctionnement repose pourtant sur une infrastructure et des centres de données mobilisant des quantités faramineuses d’énergie, d’eau, de métaux… Que sait-on aujourd’hui de son impact sur l’environnement ? On fait le point.
EBonne nouvelle ! Alors que les informations les plus farfelues circulaient ces dernières années sur la véritable empreinte environnementale de l’intelligence artificielle (IA) générative, Google a rendu, en août 2025, les résultats de ses calculs1. Le géant de la Tech révèle qu’en moyenne, une requête sur ses applications Gemini représente 0,03 g de CO₂e et 0,26 ml d’eau (5 gouttes). Plutôt rassurant, non ?
Pas si vite, car les chiffres de Google sont très inférieurs à ceux d’une autre IA générative, celle du français Mistral AI. Ce dernier s’est livré au même type d’exercice en juin dernier et révélait que l’impact d’une requête moyenne (génération d’une page de texte) sur son modèle Mistral Large 2 émettait 1,14 g de CO₂e et consommait 45 ml d’eau2… soit respectivement 40 et 170 fois plus que Gemini.
En quête de données fiables et comparables
Pourquoi une telle différence ? Il semble que les deux entreprises n’ont pas utilisé les mêmes méthodes ! Google a procédé à un calcul plutôt soft pour son image environnementale, en optant par exemple pour une requête moyenne avantageuse, en omettant d’intégrer dans ses calculs l’eau nécessaire à la production d’énergie ou en intégrant de manière discutable certains crédits carbone et d’électricité verte.
Mistral AI a au contraire procédé à une analyse reflétant la puissance de calcul nécessaire au développement de son modèle et à son utilisation, incluant les impacts liés à la fabrication des serveurs, et pas uniquement la consommation d’énergie. Un résultat plus proche de la réalité, donc.
Et du côté de ChatGPT ? Selon Sam Altman, le PDG d’Open AI, une requête moyenne équivaudrait à 0,34 Wh d’énergie, soit « environ ce qu’un four utiliserait en un peu plus d’une seconde, ou ce qu’une ampoule à haute efficacité utiliserait en quelques minutes. Elle consomme également environ 0,000085 gallon d’eau [0,32 ml], soit environ un quinzième de cuillère à café »3. Cette fois, rien sur l’empreinte carbone et aucune information sur la méthodologie utilisée.
L’arbre qui cache la forêt ?
Si cette volonté des acteurs de la Tech d’informer leurs utilisateurs sur l’impact environnemental de leur IA est plutôt encourageante, il faut se rendre à l’évidence : les efforts pour donner des informations fiables sont encore largement insuffisants.
D’abord, l’empreinte d’une requête moyenne ne dit rien de celle associée à la génération d’autres types de réponse – quelle empreinte pour une image studio Ghibli ou un starter pack, par exemple ? Ou celle d’une vidéo ? Ensuite, sans savoir quelle méthodologie a été utilisée, impossible de comparer les impacts des différentes IA. Enfin, en déterminant une empreinte « par requête », on sur-responsabilise les individus, et on laisse dans l’ombre les impacts globaux cumulés de l’IA qui constituent le vrai sujet d’inquiétude.
Car ce qui pose les problèmes les plus aigus, c’est l’énergie et les matières premières nécessaires à la construction des data centers, à leur alimentation en électricité, à leur refroidissement, au recyclage de leurs composants… et l’ensemble des conséquences néfastes que ce flux d’énergie et de matière fait peser sur le climat, les ressources en eau et la biodiversité. Et ce, d’autant plus que le nombre de data centers augmente de manière continue depuis quelques années.
Une accélération inquiétante de la demande en puissance de calcul
L’arrivée d’agents conversationnels comme ChatGPT en 2022 a en effet provoqué une croissance exponentielle du recours à l’IA, et mécaniquement une accélération sans précédent de la construction de data centers pour faire face à la demande.
On assiste à l’apparition de modèles d’IA toujours plus gros, plus consommateurs de données et nécessitant une puissance de calcul toujours plus importante.
Par exemple, entre 2018 et 2023, la taille des LLM (large language models) a été multipliée par 10 0004, et à l’échelle globale, ceci a de nombreuses conséquences néfastes pour l’environnement… dont les leaders de la Tech évitent soigneusement de parler, préférant vanter les potentialités de l’IA pour améliorer l’agriculture, les prévisions climatiques ou la protection de la biodiversité.
Une sous-estimation parfois majeure
Le cabinet de conseil indépendant Carbone 4 a étudié de près les données liées à l’entraînement de Llama, l’IA du géant Meta, pour évaluer son empreinte carbone. Selon ses calculs, si on prend en compte le périmètre complet (hors usage), ce n’est pas 9000 tCO2e qui sont associées à l’entraînement de Llama, mais 19 000 tCO2e5. Il semblerait en effet que les grands acteurs de la Tech jouent parfois avec les règles de comptabilité en effaçant la partie de leurs émissions liées à l’origine de l’électricité qu’ils consomment4.
- puces de l’encaré
Multiplication du nombre de data centers
En 2024, il y avait 8000 data centers sur la planète représentant 1,5 % (425 TWh) de la demande d’électricité mondiale, l’IA représentant autour de 10 % de cette demande.
Selon un rapport de l’Agence Internationale de l’Énergie (AIE)6, leur consommation pourrait passer à 3 % de la consommation totale d’électricité d’ici 2030 (soit près de 1000 TWh) majoritairement en raison l’expansion de l’IA et des cryptomonnaies, ce qui est colossal. Et aux États-Unis, l’IA générative pourrait représenter 50 % de la consommation d’électricité des data centers.
Si les centres de données ont besoin d’autant d’énergie, c’est qu’ils abritent les milliers de serveurs permettant le stockage des données (textes, vidéos, photos…) et le calcul (traitement et analyse de données à grande échelle grâce aux modèles d’IA. Le calcul repose sur l’utilisation d’unités de calcul spécialisées appelées GPU (graphics processing unit) capables de réaliser des millions d’opérations en parallèle.
Entraînement de l’IA : une étape particulièrement énergivore
C’est aussi dans les data centers que se déroule l’entraînement de l’IA. Elle consiste à « montrer » à des modèles des millions d’exemples (tirés d’internet en ce qui concerne les IA génératives comme ChatGPT ou Claude) afin qu’il les modélise puis soit capable de reproduire des motifs et faire ensuite des prédictions sur des données qu’il n’a jamais vues.
Cette étape énergivore et chronophage nécessite le recours des GPU de plus en plus sophistiquées, et un accès à des bases de connaissances gigantesques (internet et réseaux sociaux). Les modèles d’IA les plus en pointe ont recours à des ensembles de milliers de GPU fonctionnant en parallèle dans chaque data center. Ces « clusters » de GPU doivent être alimentés en électricité et concentrent une puissance électrique gigantesque.
La puissance des data centers était de quelques dizaines de mégawatt il y a quelques années. Elle atteint désormais plusieurs centaines de mégawatts en 2025. Les plus gros centres annoncés auront une puissance de 5 gigawatts, soit l’équivalent de la production d’une centrale nucléaire7.
Plus ces modèles sont de grande taille, plus la durée d’entraînement est longue, et plus la consommation d’électricité est importante. Et quand cette électricité n’est pas issue de sources bas-carbone (photovoltaïque, éolien, géothermie, hydraulique, nucléaire), comme aux États-Unis où il est courant de recourir au charbon et au gaz pour produire de l’électricité, les émissions carbones peuvent rapidement grimper en flèche.
Des conséquences sur les réseaux électriques locaux
Le besoin massif d’électricité va également avoir des impacts majeurs sur les réseaux de distribution et de transport qui vont être mis sous tension : épisodes de surchauffe, fluctuation de tension pouvant endommager les équipements, variation de tension et de fréquence. Sans compter que le basculement sur les alimentations de secours au fioul, dont sont équipées les data center pour éviter toute rupture d’approvisionnement, est susceptible d’entraîner des coupures en cascade.
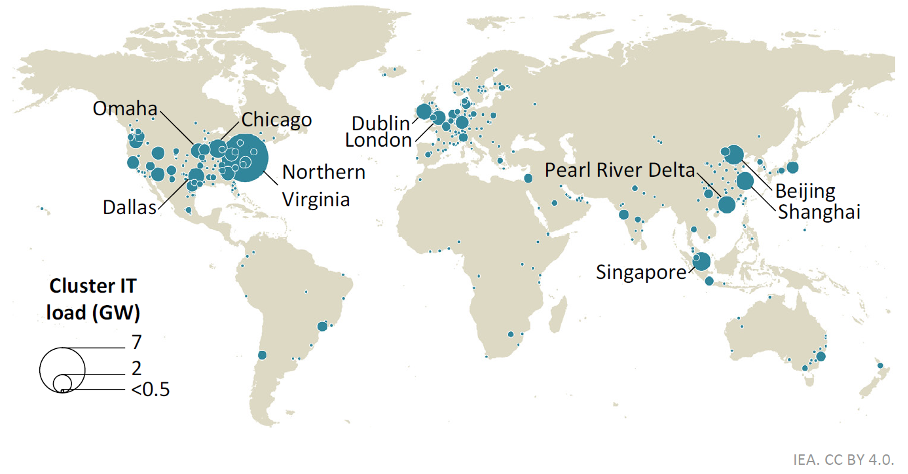
Les centres de données sont souvent regroupés en grands clusters, ce qui peut poser des défis aux réseaux électriques locaux.
Source : Rapport AIE, avril 20256
Cette pression sur les réseaux électriques incite les États, qui souhaitent rester dans la course à l’IA, à faire des investissements importants pour moderniser les réseaux électriques, avec pour conséquences davantage d’émissions carbone et de possibles augmentations de factures pour les communautés vivant à proximité des data centers entraînant une injustice sociale. Les États-Unis ont même reporté la fermeture annoncée de plusieurs centrales à charbon dans le Mississippi, en Géorgie et dans le Nebraska pour répondre à la demande en électricité de plusieurs data centers8,9.
Ce que montrent les recherches indépendantes
Il est possible de mesurer la consommation électrique des modèles d’IA dits « ouverts » (open weighs) liée à l’inférence. Les études6,10 montrent que :
- générer du texte est en moyenne 25 fois plus énergivore que classifier un spam ;
- générer une image est en moyenne 60 fois plus énergivore que générer du texte, soit de l’ordre de 1 à 3 Wh ;
- générer une vidéo de 6 secondes à 8 images/seconde nécessite environ 115 Wh, soit l’équivalent de la recharge de deux ordinateurs portables.
Optimiser pour baisser les coûts énergétiques
Pour diminuer les coûts financiers liés à l’alimentation de ces data centers, et accessoirement l’empreinte carbone, les géants de la Tech cherchent en permanence à optimiser leur consommation électrique au travers de diverses innovations : au niveau des logiciels (recours à des modèles de langage plus légers comme les Small Language Models ou SLM, quantization, pruning, distillation, Mixture of Expert MoE…), du déploiement des systèmes (batch inference, compilateurs spécialisés) ou encore du matériel et des infrastructures de calcul (GPU, puces ultraspécialisées, optimisation du Power Usage Effectiveness PUE…).
Malgré ces optimisations, la puissance requise pour entraîner les modèles d’AI — et donc les émissions de CO₂ associées — ne cesse de croître. Celle-ci doublerait chaque année selon une étude menée par des Epoch AI, un institut de recherche multidisciplinaire spécialisé dans la trajectoire de l’IA11.
Alors que l’entraînement concentre en général l’essentiel des émissions, l’arrivée des IA générative et la massification des usages, a totalement renversé l’ordre des choses. Il semble en effet qu’à partir de 100 millions d’utilisateurs – ChatGPT en a désormais 1 milliard ! –, la phase d’inférence devient plus consommatrice d’énergie que l’entraînement, avec aujourd’hui, environ 80 % de la consommation électrique des data centers dédiés à l’IA qui y est réservée.
Selon l’AIE6, les émissions de CO₂ liées à la consommation d’électricité des centres de données sont de 180 Mt (millions de tonnes) aujourd’hui, mais devraient atteindre entre 300 Mt (scénario de base) et 500 Mt (scénario d’une adoption massive de l’IA) en 2035. Et ce, sans tenir compte des émissions liées aux cycles de vie des data centers, aux équipements informatiques, à la fabrication des câbles sous-marins, à la construction des bâtiments, etc.
Une remise en cause des objectifs climatiques
Cet emballement et le besoin urgent d’alimenter les nouveaux data centers amènent non seulement le report des dates de fermeture de centrales à charbon, mais aussi la mise en place de nouveaux projets gaziers. Aux États-Unis, la construction de nouvelles centrales à gaz devrait prochainement permettre de produire 37 mégawatts (MW) d’énergie12. Google a multiplié ses émissions par deux depuis 2019 et Microsoft les a augmentées de 30%, et se situe donc 50% au-dessus de son objectif affiché. Avant l’emballement pour l’IA générative, les deux entreprises étaient pourtant sur leur trajectoire de décarbonation (voir graphique ci-dessous).
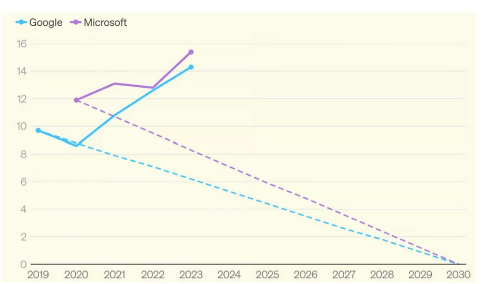
Émissions annuelles de Microsoft et Google en millions de tonnes d’équivalent CO₂, par rapport à la trajectoire moyenne requise pour respecter les engagements de neutralité carbone d’ici 2030 pris par les deux entreprises.
Source : IFP, 202413
Des besoins importants en eau
Mais la consommation électrique ne sert pas seulement à faire fonctionner les serveurs des data centers, elle sert aussi à les refroidir. Ceux-ci fonctionnent en continu et produisent en effet énormément de chaleur. Pour éviter une surchauffe, le refroidissement par air est couramment utilisé. Comme il est particulièrement gourmand en électricité, les plus gros opérateurs privilégient désormais le refroidissement par eau, tel que le refroidissement adiabatique qui consiste à asperger d’eau des surfaces traversées par de l’air chaud qui va se refroidir à son contact. Selon l’ADEME, un data center peut ainsi consommer jusqu’à 5 millions de litres d’eau par jour, soit l’équivalent des besoins quotidiens en eau d’une ville de 30 000 habitants4.
Les techniques s’améliorent cependant indéniablement. Le direct liquid cooling est par exemple une technique de plus en plus prisée par les géants de la Tech pour refroidir les grands clusters de GPU. Moins gourmande en eau, elle consiste à amener le liquide directement au contact des composants à refroidir. Elle est cependant plus coûteuse à mettre en œuvre et le recyclage de l’eau pourrait poser problème en raison de la présence de glycol4.
La quantité d’eau consommée et prélevée par les opérateurs dépend aussi du mode de production de l’électricité alimentant les data centers. Alors que l’hydraulique, le nucléaire, le charbon et le gaz nécessitent de grandes quantités d’eau pour faire tourner les turbines, le solaire et l’éolien n’en ont besoin que de très peu.
En 2023, Google aurait prélevé 28 milliards de litres d’eau (16 milliards en 2021) pour le fonctionnement de ses data centers, dont les deux tiers pour les refroidir14.
Un manque problématique de transparence
Pour connaître précisément l’impact environnemental de l’IA, différents paramètres devraient être connus : nombre d’utilisateurs, modèle de carte graphique, optimisations ou non des serveurs, nature de ces optimisations, type de data center, nature du système de refroidissement, localisation, intensité carbone du réseau électrique local… Selon une analyse récente15 :
- il n’y a aucune information environnementale sur 84 % des modèles d’IA ;
- 14 % ne publient rien, mais sont suffisamment ouverts pour que des chercheurs extérieurs puissent faire des études énergétiques,
- seuls 2 % sont des modèles transparents.
La problématique des matériaux et de leur recyclage
La fabrication des GPU, utilisées en masse dans les serveurs des data centers, implique non seulement de l’eau et de l’énergie pour être fabriquées, mais également de nombreux minerais comme l’étain, le tantale, l’or ou le tungstène, dont l’extraction est encore souvent associée à des pollutions locales. Il semblerait par ailleurs, selon certains chercheurs, que les besoins de l’IA en puces toujours plus sophistiquées font naitre de nouveaux défis, notamment un besoin de métaux de plus en plus purs impliquant une augmentation de la consommation d’énergie et un recours plus important à l’industrie chimique16.
Enfin, la multiplication des data centers pose un autre défi : celui du recyclage de ces composants. Ceux-ci contiennent des taux particulièrement importants de plomb, de cadmium et de mercure, des métaux lourds toxiques qui impliquent une gestion sécurisée de leur recyclage. Malheureusement, aujourd’hui, seuls 22 % des déchets électroniques sont recyclés correctement, le reste finissant dans des décharges informelles des pays du sud avec tous les risques de contamination des travailleurs que cela comporte.
Selon une étude de Nature publiée fin 2024, l’IA pourrait être à l’origine d’un supplément de déchets électroniques équivalents à 5 millions de tonnes s’ajoutant aux 60 millions déjà produits aujourd’hui17.
Vers une IA frugale ?
Pour conclure, si l’IA est un outil puissant qui pourrait contribuer à résoudre certains des défis environnementaux auxquels nous sommes confrontés, force est de constater que son développement exponentiel et rapide va à l’encontre de l’intérêt collectif et de nos ambitions climatiques. Seule une approche combinant efficacité matérielle et questionnement des usages pourrait avoir du sens dans le contexte environnemental actuel.
L’IA frugale, fondée sur la nécessité, la sobriété et le respect des limites planétaires, pourrait constituer un levier central pour concilier innovation et durabilité. Portée par la stratégie nationale française depuis 2025, elle vise à réduire l’empreinte écologique des systèmes d’IA tout en maintenant leur performance. Le référentiel AFNOR Spec 2314, fruit d’un large travail d’expertise, offre des outils concrets pour évaluer et limiter cet impact18.
Sources
1. How much energy does Google’s AI use? We did the math, Google Cloud, August 2025
3. The Gentle Singularity, Sam Altman Blog, june 2025
5. L’IA Générative… du changement climatique ! Carbone4, mars 2025
7. Here’s the 5GW, 30 million sq ft data center pitch doc OpenAI showed the White House
8. Southern Company to extend life of three coal plants due to data center energy demand, February 2025
9. A utility promised to stop burning coal. Then Google and Meta came to town.
10. Power Hungry Processing: Watts Driving the Cost of AI Deployment? Luccioni 2024
11. The power required to train frontier AI models is doubling annually, 2024
12. Global Oil and Gas Plant Tracker, Global Energy Monitor, 2025
13. How to Build the Future of AI in the United States, IFP, October 2024
14. Google Environmental Report 2023
17. E-waste challenges of generative artificial intelligence, October 2024
18. IA frugale, EcoLab, mai 2025
Par Véronique Molénat, rédactrice scientifique